
 >
>基于数字化卡登格的生成图像隐写方案
时间:
摘要:针对图像隐写中载体修改会留有修改痕迹的问题,文章提出一种基于数字化卡登格的图像隐写方案。首先自动生成数字化卡登格,作为信息隐写和提取的密钥;其次以空白图像作为载体,根据数字化卡登格的区域填充秘密信息;在整个隐写过程保持秘密消息不变的情况下,再利用深度生成模型补全受损的图像,生成具有自然语义的含密图像。文章方案不受载体类型的限制,还可以扩展到其他数字媒体。实验结果表明,新的图像隐写方案具有良好的可行性,相比其他隐写方法,文中方案在实际通信中安全性较高。
关键词:图像隐写;数字化卡登格;图像补全;生成对抗网络
0引言
近年来,随着数字媒体的广泛使用和互联网的普及,隐写技术得到飞速发展,同时也面临前所未有的挑战。长期以来,载体修改是传统隐写术最常见的方法,该方法导致含密载体总会留下修改痕迹。尽管采用各种技术来掩盖修改痕迹,仍难以从根本上抵抗基于统计特性的隐写检测[1]。
随着深度学习技术的进步,深度生成模型成为当前数字信息领域研究的热点之一。深度生成模型最大的优势在于能够生成多样化的样本,理论上能够保证生成的样本特征无限逼近真实样本的特征,因此深度生成模型被迅速应用到隐写技术领域。2019年4月11日,以“信息隐藏与人工智能”为主题的香山科学会议上,有学者提出利用生成对抗网络(GenerativeAdversarialNetworks,GAN)自动生成图像,应用于隐写技术[2]。
目前深度生成模型主要应用于图像合成领域,该模型对图像隐写的研究具有先天优势。在LIU[3]等人工作的启发下,结合深度生成模型,本文提出了一种基于数字化卡登格的图像隐写方案。首先自动生成数字化卡登格,作为信息隐写和提取的密钥;其次以空白图像作为载体,根据数字化卡登格的区域填充秘密信息;在整个隐写过程保持秘密消息不变的情况下,再利用深度生成模型补全受损的图像,生成具有自然语义的含密图像。
1相关知识
我国古代文献记载了一种巧妙易用的隐写方法,发送者和接收者各自持有一张带有许多小孔的纸,纸中小孔的位置相同且是随机选择的。发送者在这张纸上盖一个孔,将机密信息写在小孔的位置,然后移去上面的纸,根据纸上留下的字和空余位置,编写一段具有普通逻辑意义的文本。16世纪初期,意大利数学家Cardan也发明了这种方法,该方法被称作卡登格子法[4]。由于不便用于数字隐写,此方法逐渐被其他隐写技术所代替,但其核心思想一直被隐写研究人员奉为经典方法之一。
随着计算机硬件和运算能力的大幅提升,隐写术取得巨大进步,同时也面临严峻挑战。以机器学习、人工智能为代表的新兴技术被广泛应用于信息隐藏领域,特别是基于深度学习技术的隐写技术层出不穷。例如,VOLKHONSKIY[5]等人首次提出利用GAN进行隐写的SGAN方案,王耀杰[6]等人提出了ImprovedSSGAN方案,KE[7]等人提出了生成式隐写的概念。
根据不同的含密方式,FRIDRICH[8]将隐写信道分为3类:载体修改、载体选择及载体合成。其中,载体修改是传统隐写术最常见的方法。在深度生成模型出现之前载体合成隐写方法是十分困难的,仅在理论上提出构造。LIU[3]等人在此基础上提出基于载体合成的数字化卡登格隐写方法,继续沿用传统卡登格的核心思想,并将卡登格与生成模型结合起来,迅速引起了研究者的关注,多种衍生改进算法相继被提出。基于数字化卡登格的典型隐写算法有:
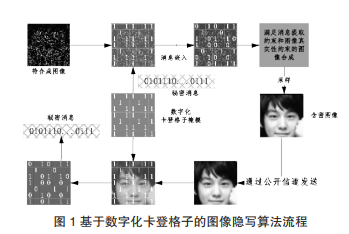
1)LIU[3]等人利用生成对抗网络中的生成模型,提出一种基于数字化卡登格的图像隐写算法。该算法根据传统的卡登格思想,从损毁图像出发,在图像固定损毁区域嵌入秘密消息,并将含有消息的损毁图像作为约束条件,利用图像补全技术进行图像合成,生成具有自然语义的含密图像。该算法利用双方共享的卡登格进行消息嵌入和提取,整体流程如图1所示。
该算法首次将基于对抗网络的图像合成技术应用到信息隐藏领域,使得基于图像合成的隐写方法从一种理论构造,变为一种切实可行的技术方案。该算法不依赖于某个特定的载体,含密图像实际上是从生成器的分布中采样得到的,因此具有一定的抗统计分析能力,但是该算法依赖于GAN的生成效果,同时消息提取的正确率不能得到保证。2)刘明明[9]等人利用ACGAN[10]中的生成模型,提出基于标签矩阵的卡登格子隐写算法。该算法利用ACGAN能够根据标签矩阵生成指定图像的特性,首先使用双方共享的卡登格子将秘密消息嵌入到标签矩阵,然后输入到生成模型中生成含密图像,实现了传统卡登格信息隐藏的自动化操作。该算法整体流程与文献[3]相似,如图2所示。
该算法将密码学中简单的单表代替与信息隐藏相结合,实现了满足Kerckhoffs准则[11]的数字化卡登格隐写方法。相比传统卡登格,本文利用GAN自动生成格子载体,避免了人工构建格子载体。同时,生成的图像具有实际内容,符合信息隐藏的基本要求。但该算法嵌入容量较小、容差性能差,不能真正满足现实隐蔽通信的需要,当使用频数过多时存在安全隐患。
2基于数字化卡登格的隐写方案
借助生成对抗网络技术,本文提出一种基于数字化卡登格的生成式图像隐写方案,整体方案框架如图3所示。接收双方共同定义一个掩码,称为数字化卡登格,用来确定秘密消息的嵌入位置,扮演密码学中密钥的角色。首先根据数字化卡登格对应的“1”位置(省略“0”位置),将秘密信息预先写入空白图像,且整个隐写过程中上述信息保持不变。然后将含密的破损图像输入到生成对抗网络中,生成具有自然语义的含密图像。含密图像通过公共信道发送给接收者,接收者使用共享的数字化卡登格逆向提取秘密消息。
本文方案主要包括3部分:数字化卡登格的设计原理,数字化卡登格的自动生成以及嵌入信息后的破损图像补全。隐写的载体可以是任何数字对象,不局限于图像隐写。
2.1数字化卡登格的设计原理
在本文中,数字化卡登格仍然采用传统卡登格的思想,通过Hadamard乘积[12]实现传统卡登格到数字化卡登格的转换。Hadamard乘积是一种矩阵乘法运算,假设A=(aij)和B=(bij)是相同阶数的两个矩阵,如果cij=aij×bij,则矩阵C=(cij)称为A和B的Hadamard乘积,表示为ABe,如公式(1)所示。
根据Hadamard乘积的运算过程,数字化卡登格的设计过程为假设A表示秘密消息,B表示二进制掩码的卡登格(只能用0和1表示),可通过Hadamard乘积进行秘密消息的隐藏和提取。如图4所示,以2×2像素的简单图像为例,在隐藏过程中,空白图像会被数字化卡登格覆盖。值为“1”的位置代表传统卡登格中的小孔,意味着可以嵌入消息;值为“0”的位置代表没有孔,表示此位置不嵌入消息。嵌入消息后的破损图像输入到GAN中进行语义补全,如图4a)所示。提取消息时,接收方采用相同的数字化卡登格,通过Hadamard乘积恢复出秘密消息。值为“1”的位置表示需要保留的图像消息,值为“0”的位置表示需要丢弃的图像消息,也就是说,通过Hadamard乘积所得消息就是嵌入的秘密消息,如图4b)所示。对于第三方而言,数字化卡登格的消息是严格保密的。
2.2自动生成数字化卡登格
传统的卡登格方案,需要在秘密消息的基础上人工构造一个有意义的载体,如藏头诗,费时费力。数字化卡登格的自动生成,不仅能够满足现实隐蔽通信的需求,而且可以提高信息的安全性,大大增加了第三方破译的障碍。
根据数字化卡登格的设计原理,本文采用密码学中的消息摘要算法[13]进行自动生成数字化卡登格。消息摘要算法主要应用于数字签名领域,其主要特征是具有唯一性和不可逆性。常见的摘要算法包括MD5算法、SHA-1算法、SHA-256算法以及大量衍生变体。本文以SHA-1算法为例,对数字化卡登格自动生成步骤解释说明,如图5所示。
SHA-1算法可以输出20B的哈希值,通常在哈希表中以40个十六进制数字的形式进行表示。自动生成数字化卡登格主要包含4个步骤:
1)获取约定好的公共信息作为输入信号。根据不同的时间获取的公开信息是不同的,如每天《华尔街日报》头版的标题(本身包含时间戳信息),对信息进行二进制编码。
2)填充密钥。接受双方预先共享相同的密钥,并根据约定的规则对编码后的公开信息进行填充(图5所示为尾部填充,仅作为原理解释)。
3)加密。填充后的信息输入到SHA-1生成器中,输出20B的消息摘要散列值。
4)对步骤3)中消息摘要进行顺序排列构成矩阵,记为数字化卡登格。根据嵌入的秘密信息的数量,丢弃多余的位数。如果矩阵位数不够填充整个矩阵,则剩余部分填充“0”。
2.3补全含密图像
近年来,图像补全技术层出不穷[14]。本文中需要补全的图像破损率占95%以上,即不是常规破损图像的少量修复,而是大规模的图像生成。在文献[3]和文献[15]启发下,本文使用YEH[16]等人基于深度卷积生成对抗网络(DCGAN)[17]的图像修复方法,并调整了部分参数以确保生成的图像满足语义需求。
3实验与分析
为了验证该方案的可行性和安全性,实验中分别采用CelebA数据集和LSUN数据集训练网络模型。前者由香港中文大学公开提供,被广泛用于计算机视觉训练任务,包括200000张图像。后者是由深度学习构造的大规模图像数据集,包含10个场景类别和20个对象类别,每个类别都有大约1000000个带标签的图像。
实验环境如表1所示。实验中采用YEH[16]等人提出的DCGAN模型架构,其中优化模型使用基于Adam的优化方法,学习率为0.0002。在每次训练中,判别模型D的权重需更新一次,生成模型G的权重更新两次[18]。
首先对图像进行预处理[19],将图像裁剪为128×128像素,在文献[16]的基础上,对具体参数进行修改。假设在每张空白图像上嵌入的消息随机分布在16个像素上,图6a)是训练11个周期后生成模型补全CelebA数据集图像的示例;图6b)是训练7个周期后生成模型补全LSUN数据集图像的示例。
为了更好地评估生成图像的质量特性,本文引入了无参考图像质量评估(NR-IQA)方法[20]。该方法不需要与原始图像进行比较,同时基于生成模型的图像隐写术没有原始载体,因此NR-IQA方法与基于生成模型的图像隐写术在评估特性上是完全一致的,弥补了目前传统隐写术评估体系的不足。在视觉效果没有异常的情况下,通常使用幅频图、频率直方图、DCT系数直方图等作为无参考评估手段。从本文方案补全的图像中随机选取示例的实验数据如图7所示。通过仿真实验表明,本文所补全的样本在频率特性、DCT系数等方面完全符合自然图像的常规统计规律,没有出现异常统计频率值,可有效抵抗基于统计隐写分析的检测,基本满足现实隐蔽通信的需求。
为进一步验证补全后含密图像的抗检测性,本文选择当前主流检测算法进行对比和分析。从CelebA数据集和LSUN数据集中随机选择6000张真实图像,并使用本文算法生成的4000张图像作为测试集。选择的4种隐写检测算法分别为DCT域隐写分析法[21]、RS检测法[22]、非线性SVM检测法[23]和S-CNN检测法[24]。DCT域隐写分析法主要关注DCT系数的统计特性及其对空间像素的影响。RS检测法(常规组和奇异组)主要评估图像的灰度值。非线性SVM检测法的实质是提取样本的特征数据,作为一种二元分类模型。S-CNN检测法是使用卷积神经网络进行图像检测的最新方法。在随机分组独立测试的情况下,隐写检测的实验结果如表2所示。
除S-CNN检测法外,其他3种检测算法的检测准确率均接近0.5,表明本文方案在检测抗性方面具有很大的优势。对于S-CNN检测方法,其检测准确率趋近0.65,需要进一步提高。在现实的通信过程中,可以通过减少嵌入容量来更好地满足不可感知性,从而保证隐写术的通用性。——论文作者:王耀杰1,2,杨晓元1,2,刘文超1,2
本文来源于:《信息网络安全》(月刊)创刊于2001年,由公安部第三研究所、中国计算机学会计算机安全专业委员会主办。是由公安部主管,公安部第三研究所、中国计算机学会共同主办的信息网络安全领域中的一本综合性刊物。设有:特别报道、国内网事、安全论坛、技术市场、法苑阡陌、名人访谈、媒体综述、安全驿站等栏目。
