
 >
>引入圈闭加合法的多统计法联合计算油气资源量探讨
时间:
摘要:区带油气资源量计算常用到统计法,主要包括规模序列法、发现过程模型法、广义帕莱托法等,但这3种方法在油气资源评价过程中均存在油气藏数量难以确定的问题。为了更精确、合理地计算区带油气资源量,首先通过圈闭加合法分析和预测区带中未发现的大一中型油气藏,然后根据已发现与未发现大一中型油气藏的储量规模序列计算区带油气藏数量,最后根据已确定的油气藏数量采用多统计法联合计算区带油气资源量。通过使用圈闭加合法分析大一中型油气藏储量规模,并计算得出区带油气藏数量,解决了油气藏数量确定这一关键问题,而多统计法的联合使用更进一步提高了油气资源量计算结果的准确性。
关键词:多统计法圈闭加合法关键问题油气藏数量大一中型油气藏油气资源量
油气资源评价结果是石油工业发展、规划和决策的重要依据。目前油气资源评价已发展为一个相对完整的科学体系,其理论已较为成熟,评价方法多达百余种n‘41,总体可分为成因法、统计法和类比法3大类,这3大类评价方法的应用范围和侧重点也存在差异。
在区带级的油气资源量计算过程中通常会用到统计法[5娟],并且为了提高计算结果的准确性,会使用多种不同的统计法进行联合计算,如准确性较高的规模序列法、发现过程模型法、广义帕莱托法等。虽然这几种统计法应用程度较高,基础理论相对成熟,但仍然存在一些问题,特别是在这些方法同时使用的情况下;例如对同一区块进行油气资源量计算时,使用不同的统计法所得到的计算结果会存在较大的差异,甚至出现部分油气资源量评价参数不符合实际地质情况。为此,笔者通过分析统计法应用过程中存在的关键问题,提出相关优化方案,提高了多统计法联合计算油气资源量的准确性,研究成果可以为今后的油气资源评价工作提供借鉴。
1统计法应用过程中存在的关键问题
统计法是一种利用已知油气资源分布来预测整体油气资源分布的方法,可通过不同的函数模型得到不同的预测结果。例如规模序列法、发现过程模型法、广义帕莱托法即为根据已发现油气地质储量,通过函数模型计算整体油气资源分布的方法。
统计法实质上是一种数据法,通过分析例如储量规模、探井进尺、探井成功率、单井发现率等统计数据来计算油气资源量,因此其计算过程一般不具有地质意义,即无法以地质经验去验证其计算结果的准确性。不同的统计法所采用的函数模型不同,因此所得到的结果也会有一定的差别。即使利用同一组统计数据,如果使用不同的统计法,也会导致计算结果存在差异。例如同一组储量规模数据,使用规模序列法和发现过程模型法得到的最终结果肯定不同,其原因为真实的储量规模序列是1个非常复杂的函数,仅依据目前的认识与计算方法并不能建立准确的函数模型,只能通过现有的函数模型进行多次模拟,得到1个储量分布范围,且若使用的统计法越多,计算结果的准确性越高。因此,可以说区带的油气资源分布是不可模拟的,应用统计法的计算过程只是一个不断逼近油气资源量真实值的过程,且应用的统计法越多,得到的油气资源量分布区间越集中,表明计算结果越接近真实值。
笔者采用规模序列法、发现过程模型法和广义帕莱托法3种方法联合计算区带油气资源量;但这3 种统计法都具有1个相同的关键参数,即区带的油气藏数量,对油气藏数量的确定也是统计法计算油气资源量的关键问题。因此,多统计法联合计算油气资源量的前提条件为区带的油气藏数量必须一致,且必须符合实际油气藏的分布特征。
1.1规模序列法
规模序列法是目前最常用的统计法,使用的前提条件为已发现区带内最大型的油气藏。该方法的原理是基于统计结果,即在1个独立的石油地质单元内,对已存在的油气藏的储量规模进行排序,在双对数坐标中以油气藏储量规模序列号为横坐标、油气藏储量规模为纵坐标,其关系大致为一条直线。
在利用规模序列法计算实际油气资源量的过程中,同一组储量规模数据可能会预测得到多条连线,即符合预测条件的储量规模数据点连线的斜率变化范围很大。如图1所示,同一组已发现油气藏储量规模序列可以拟合出3条油气藏储量规模数据点连线,即可以预测出3种油气资源量分布情况。因此,即使是在区带内最大型油气藏已确定的情况下,油气藏数量与总油气资源量仍存在很大的不确定性。因此,对于油气藏数量的确定仍是该方法应用的重点与难点。
1.2发现过程模型法
该方法的基本原理为利用在总体中进行抽样得到的样本信息对总体特征进行估计,因此,可以将1个区带中可发现的油气藏作为1个有限的总体,再把已发现的油气藏作为从总体中抽取的样本信息,这样就可以利用这组样本信息推断出总体的特征,即达到油气资源评价的目的睛]。Kaufman等提出通过发现过程模型来处理油气藏储量规模数据,即可以利用有偏样本来估算油气藏储量规模凹1。应用发现过程模型从有偏样本(偏向于大型油气藏) 中估算油气藏储量规模与分布,须首先估算油气藏储量规模的对数正态分布平均数和方差,并得到这 2个参数分布的百分比,从而得到油气藏储量规模的整体概率密度函数。当区带油气藏数量为已知,且已确定油气藏储量规模分布时,即可以通过分级方式来估算油气藏的储量规模n…“。
相关知识推荐:论文里的单位信息写哪些
同样在应用发现过程模型法过程中,同一组已发现油气藏储量规模序列可以拟合出多种油气藏的油气资源量分布情况,即当区带油气藏数量不确定时,预测结果也存在较大变化。因此,在使用该方法计算油气资源量时,须首先确定油气藏数量。
1.3广义帕莱托法
对于勘探程度较高的地区,可以将其已发现油气藏按照储量规模划分为具有一定函数分布关系的储量级别或区间。统计已发现油气藏在不同储量区间的分布个数,结果表明,随着油气藏储量规模的增大,其发育数量逐渐减少,这种具有函数关系的分布特征即为帕莱托分布。1
广义帕莱托法涉及到的最小油气藏储量规模、最大油气藏储量规模以及油气藏储量规模样本中位数等关键参数可以根据已发现油气藏储量规模样本数据获得,且这些参数的取值较易于确定。但油气藏储量规模分布系数经常为不确定值,其取值变化与油气藏数量有关。对于同一组已发现油气藏储量规模序列,由于不同的油气藏数量,可以得到不同的油气藏储量规模分布系数,且最终预测油气藏的油气资源量分布情况也会出现多种结果,因此确定油气藏数量也是广义帕莱托法的重点。
综上所述,多统计法联合计算油气资源量的关键问题为区带油气藏数量的确定。
2油气藏数量确定与油气资源量计算
针对如何确定油气藏数量的问题提出以下解决思路:虽然在使用统计法时不易确定油气藏数量,但是对于部分已发现的大一中型油气藏(储量规模超过100x 104 t)的数量及储量规模是可以确定的。因此,可以通过分析已发现的大一中型油气藏来推导区带油气藏储量规模序列中未发现的大一中型油气藏,并据此推测油气藏数量。
2.1油气藏数量确定
利用圈闭加合法可以计算区带已发现与未发现大一中型油气藏的油气资源量。圈闭加合法的实质就是将研究区所有圈闭中的油气资源量进行加积计算,即首先计算不同级别圈闭的油气资源量,然后通过加合所有圈闭油气资源量得到区带的总油气资源量。其计算过程是首先通过分析已发现的圈闭油气资源量得到单储系数、油气资源丰度等参数,然后分析潜在圈闭(已进行圈闭评价)与推测圈闭(未进行圈闭评价)得到未发现圈闭的数量、含油气面积和有效储层厚度等参数,最终计算得到未发现圈闭的油气资源量[12‘13I。
需特别指出的是,圈闭加合法是区带油气资源量预测的方法之一,笔者进行多统计法联合计算油气资源量分析的1个前提假设条件即为应用圈闭加合法时认为已发现的大一中型油气藏均为真实存在的,显然该假设条件是不可能完全实现的,因此,就涉及到另1个关键问题,即圈闭勘探成功率的确定。当圈闭勘探成功率足够高时,应用圈闭加合法预测得到的大一中型油气藏可以近似地认为是真实、可靠的;而当圈闭勘探成功率较低时,应用圈闭加合法预测得到的大一中型油气藏不是真实存在的。因此,利用圈闭加合法计算大一中型油气藏油气资源量的准确性与圈闭勘探成功率相关。然而在实际勘探工作中,圈闭勘探成功率为0或100%都是不可能的,通常中一高勘探程度地区的圈闭勘探成功率为60%~80%[14。引(图2)。笔者将圈闭勘探成功率的取值定为70%,并将其应用于油气资源量的计算,得到未发现大一中型油气藏的储量规模。而在中等勘探程度地区,圈闭勘探成功率通常为 30%一50%‘14-15],以圈闭勘探成功率为40%来计算油气资源量。因此,在应用圈闭加合法计算圈闭油气资源量过程中,需将所计算的大一中型油气藏圈闭油气资源量乘以圈闭勘探成功率以转化为储量规模,即将高勘探程度地区的潜在圈闭油气资源量计算结果乘以70%,中等勘探程度地区的推测圈闭油气资源量计算结果乘以40%。
根据大一中型油气藏储量规模序列可以确定区带的油气藏数量,包括已发现的大一中型油气藏储量规模序列与圈闭加合法计算得到的未发现大一中型油气藏储量规模序列。将大一中型油气藏储量规模序列作为样本数据代人规模序列法、发现过程模型法、广义帕莱托法的计算公式中,当计算结果中有l组预测油气藏储量规模序列适用于这 3种方法时,所计算得到的油气藏数量即为预测区带的油气藏数量。但有时可能会得到多组适合的结果,考虑到可信度等问题,通常选择油气藏数量最少的那组数据。
2.2油气资源量计算
根据最终获得的区带油气藏数量即可以进行油气资源量计算。由图3可以看出,在9个大一中 型油气藏中有7个为已发现油气藏,2个为利用圈闭加合法预测的未发现大一中型油气藏,而32个油气藏储量规模序列为满足多统计法计算油气资源量的最佳结果。根据9个大一中型油气藏与32个油气藏即可计算区带的油气资源量,在32个油气藏储量规模序列中,后19个油气藏储量规模序列为多统计法计算所得到的。可见虽然在应用规模序列法、发现过程模型法、广义帕莱托法时所采用的油气藏数量是一致的,但计算的油气藏储量规模不一致。因此,实际区带油气资源量应位于3种统计法计算结果的区间范围内。
最终区带油气资源量计算结果可以利用特尔菲法n73进行计算(图3)。需指出的是,通过特尔菲法计算的区带油气资源量仍不能代表实际油气资源量,仅是更接近于真实值。当增加新的计算方法时,计算结果也会发生调整,且更加接近于真实值。
3实例应用
以菜油田L区为例,该区目前勘探程度较高,面积为257 km2,三维地震已覆盖全区。截至2014年底,已完钻各类探井98口,总进尺为293 775 m;已发现27个油藏,探明石油地质储量为650.09x104 t,三级石油地质储量总计807.74x104 t,已完成未钻探圈闭的评价工作。
3.1大一中型油藏数量确定
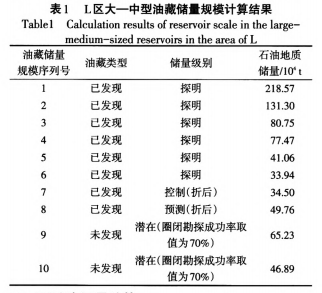
对L区大一中型油藏(储量规模大于30x10't) 进行统计分析,并将其控制和预测石油地质储量按照O.75和o.5进行折算。采用圈闭加合法剖析研究区已发现大一中型油藏,确定其石油单储系数为 12.21X104 t/(km2·m),圈闭含油面积系数为38.1%,储层含油系数为8.7%,储层平均厚度为110 m;进而得出未发现油藏中储量规模大于30x104 t油藏的圈闭面积需大于2.3 km2。通过对L区有利构造进行圈闭预测,确定有2个圈闭面积大于2.3 km2,即研究区有2个未发现大一中型油藏。将圈闭加合法的计算结果乘以70%的圈闭勘探成功率,最终确定2个未发现油藏的储量规模分别为65.23x 104和46.89x 10' t。因此,L区大一中型油藏的数量为10个(表1)。
3.2石油资源量计算
将利用圈闭加合法确定的研究区储量规模大于30x104 t的lO个大一中型油藏的储量规模序列作为规模序列法、发现过程模型法、广义帕莱托法3种统计法的计算参数。同时考虑研究区目前勘探开发成效,设定以油藏储量规模为5x10't作为勘探下限,可确定当油藏数量为47个时,利用多统计法联合计算油气资源量的效果最佳。因此,L区预测油藏数量为47个,最大油藏储量规模为218.57x104 t,最小油藏储量规模为5×104 t,分别采用规模序列法、发现过程模型法、广义帕莱托法计算石油资源量,结果(图4)表明,3种统计法所得的计算结果分别为1 443,1 261和1 332x104 t。考虑计算结果与真实值的吻合程度,采用特尔菲法对3种统计法的计算结果进行加权计算。由于广义帕莱托法为最佳拟合方法,其预测石油资源量在3个计算结果中处于中间值,因此,将其权重系数调整为0.5,其他2 种统计法计算结果的权重系数为0.25,最终确定L 区的石油资源量为1 342×1 04 t。
此外,通过理论分析及实例应用,认为圈闭加合法是区带油气资源量预测的方法之一,其计算结果为预测油气资源量,存在不确定性,通常不能作为实际油气藏的油气资源量来进行统计。而随着勘探程度的提高,特别是在高勘探程度地区,大一中型油气藏已基本勘探开发,使用圈闭加合法计算发现的大一中型油气藏数量很少,因此在高勘探程度地区这种不确定性较小。即使在中等勘探程度地区,使用圈闭加合法计算大一中型油气藏时,通过加入圈闭勘探成功率也能很好地降低这种不确定性。因此,虽然圈闭加合法存在一定的不确定性,但是随着勘探程度的提高以及研究资料的不断增加,其油气资源量计算结果可以不断得到修正,使其更加精确。
4结论
利用规模序列法、发现过程模型法、广义帕莱托法这3种统计法计算油气资源量过程中均存在油气藏数量这一关键参数,且该参数的确定也是采用多统计法联合计算油气资源量过程中的关键问题。首先通过圈闭加合法分析区带大一中型油气藏,然后以大一中型油气藏储量规模序列来确定适用于多统计法的油气藏数量,进而使用多统计法联合计算油气资源量。利用圈闭加合法计算区带油气藏数量,可以解决多统计法联合计算油气资源量过程中油气藏数量确定这一关键问题,进而有效地提高油气资源量计算结果的准确性。——论文作者:赵迎冬1,张永超1,臧梅2,王建伟1,白琨琳3
