
 >
>公共卫生类核心期刊论文常见单因素统计推断问题调查与分析
时间:
摘要:目的了解公共卫生领域核心期刊论文的单因素统计推断问题的发生情况,提出对策建议,为降低文章单因素统计推断错误发生率,提高文章质量提供参考。方法采用目的抽样选取四种公共卫生领域期刊,检索其2019年度刊登的全部文章,对文章逐篇阅读并记录、分析其单因素统计推断应用情况。结果本次研究共调查2023篇文章,最终纳入1139篇文章,出现单因素统计推断错误的文章共53篇,单因素统计推断错误率达4.65%,主要错误类型为资料不满足正态性和(或)方差齐性误用t检验或方差分析、理论频数太小误用χ2检验、重复测量资料误用成组t检验等。结论公共卫生类期刊论文单因素统计推断应用正确率有待提高,研究者、编辑、审稿专家及期刊编辑部应加强统计学知识学习,把握论文发表各环节,以促进公共卫生领域期刊论文质量的提高。
关键词:公共卫生类期刊;单因素统计推断;统计学错误
统计推断是通过样本推断总体的统计方法[1],根据所研究因素的数量不同可分为单因素统计推断和多因素统计推断[2]。常用的单因素统计推断方法有t检验、χ2检验、单因素方差分析等。单因素统计推断作为多因素分析的基础,常用于医学研究的统计分析中,准确选择和使用单因素分析方法是保证医学研究科学性的前提。曾有研究人员对部分医学论文中出现的统计学错误进行分析,发现随着统计学方法在医学论文中的使用愈发频繁,部分研究者因不熟悉统计学方法而出现的误用、滥用的现象亦逐渐增多[3-7]。但因研究时间较为久远、研究范围较为宽泛,这些研究已无法充分反映当前公共卫生类期刊论文中出现的统计学问题。本研究选取数本国内公共卫生与预防医学领域的专业学术期刊,旨在了解权威期刊中常见的单因素统计推断方法的应用情况,探讨其中存在的统计学问题,以期引起卫生相关工作人员对正确使用统计学方法的重视,并采取有效措施以提高学术论文的质量。
1材料与方法
1.1研究对象本研究采用目的抽样法,选取了国内公共卫生领域的四种核心期刊,分别为《中华流行病学杂志》、《现代预防医学》、《中国公共卫生》和《中华预防医学杂志》,并检索其2019年度刊登的全部文章。
1.2纳入与排除标准四种期刊中凡应用了单因素统计推断方法的文章,均纳入本次研究。对下列类型的文章进行排除:①会议论文;②案例报道。
1.3分析方法逐篇阅读符合纳排标准的文章,记录并分析其单因素统计推断的应用情况。绘制柱状图展示文章的单因素统计推断问题分布情况,计算本研究中公共卫生类期刊论文单因素统计推断错误发生率(本研究中出现单因素统计推断错误的文章篇数/纳入的文章篇数)反映总体错误情况,并与同类研究结果进行比较。
2结果
2.1总体情况本次研究共调查2023篇文章,最终纳入1139篇文章,出现单因素统计推断错误的文章共53篇(错误共55处,其中2篇文章同时出现两类单因素统计推断错误),错误率达4.65%。其中,出现的单因素统计推断错误类型主要有资料不满足正态性和(或)方差齐性误用t检验或方差分析、理论频数太小误用χ2检验、重复测量资料误用成组t检验、多组均数的比较采用t检验且未进行检验水准校正等,具体错误分布情况见图1。
2.2具体问题分析
2.2.1资料不满足正态性和(或)方差齐性误用t检验或方差分析t检验和方差分析为定量资料分析中较为常见的假设检验方法,常用于均数的比较。t检验的应用条件为:①在单样本t检验中,总体标准差!未知且样本含量较小时,要求样本来自正态分布总体。②配对t检验是单样本t检验的特殊情况,应用条件为差值服从或近似服从正态分布。③使用成组t检验对完全随机设计两样本均数进行比较时,要求两样本均来自正态分布总体,且两样本总体方差相等;若两样本总体方差不相等,则用t’检验或非参数检验。单因素方差分析的应用条件为:①各样本是相互独立的随机样本,均服从正态分布。②各样本的总体方差相等[8]。本研究中与这两种方法相关的问题主要有:①在进行完全随机设计t检验或方差分析时,部分数据不满足总体方差相等的要求,且未对不满足要求的数据分别进行t’检验或非参数检验。②在涉及单样本t检验时,未对部分样本量较少的数据的正态性进行说明。
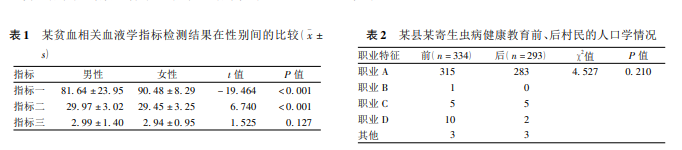
案例:为探讨某市育龄夫妇某种贫血的筛查结果,研究者通过统计当地育龄夫妇筛查数据,比较不同性别间相关血液学指标检测结果来分析该市育龄人群患该类型贫血的筛查情况。研究分别纳入男性3108人,女性3108人,采用t检验比较性别间的指标差异,结果以均数±标准差表示。结果见表1。
笔者使用方差齐性检验判断不同性别人群的指标一检测结果是否方差齐,经计算F=8.35,v1=3107,v2=3107,P<0.05,说明该组数据不满足方差齐性要求。处理该类数据,首先应进行正态性检验,若其来自正态分布总体,则可进行下一步;若总体偏离正态,需作数据转换以改善其正态性或选用其他的统计分析方法。随后再进行方差齐性检验,可利用Bartlettχ2检验或Levene检验,若数据符合方差齐性要求则可进行方差分析;若不满足则应采用非参数检验。
2.2.2理论频数太小误用χ2检验χ2检验为定性资料分析中较为常见的假设检验方法,常用于率或构成比的比较。完全随机设计四格表资料的χ2检验应用条件为:①当n≥40,且T≥5时,可直接采用四格表卡方检验进行分析。②当n≥40,且有1≤T<5时,应采用校正后的χ2值,也可用四格表的Fisher确切概率法。③当n<40或有T<1时,应选用Fisher确切概率法。完全随机设计R×C列联表资料的χ2检验则要求理论频数不宜太小(有1/5以上格子的理论频数小于5,或有1个格子的理论频数小于1),否则有可能导致分析的偏性[8]。本调查发现部分研究在使用该统计方法进行分析时,部分数据的理论频数或样本含量过小,不满足"2检验的适用条件。
案例:为探究某县某寄生虫病健康教育效果,某研究者在实施教育前后分别进行问卷调查,在分析研究对象的人口学特征时,采用完全随机设计R×C列联表资料的χ2检验比较村民职业特征分布情况。数据见表2。
相关知识推荐:公共卫生类核心期刊投稿方法
表中的职业B群体在进行健康教育前、后的人口理论频数分别为0.53和0.47,均小于1,理论频数过小不能直接采用完全随机设计R×C列联表资料的χ2检验。对理论频数太小的数据,可通过增大样本含量,以达到增大理论频数的目的;或将理论频数太小的行列与性质相近的邻行邻列合并,通过将相应的实际频数相加,使重新计算的理论频数增大;也可使用确切概率法[9]。以Fisher确切概率法为例,笔者计算得到的值为5.436,P=0.203,说明健康教育前后该县村民的职业特征分布差异无统计学意义。
2.2.3重复测量资料误用成组t检验重复测量资料是指对同一研究对象的同一结局指标在不同时间点或不同条件下进行多次测量获得的数据,处理重复测量设计资料常应用纵向数据统计模型如重复测量资料方差分析、广义估计方程或(广义)线性混合模型等[10]。本研究发现部分学者选用统计学方法时忽视了数据类型,例如比较重复测量资料时仍使用成组t检验。
案例:某研究者为探究某教育对产妇哺乳情况的影响,随机将120名产妇分为对照组和干预组,对照组产妇出院给予常规指导,干预组产妇出院指导除常规内容外增加某教育内容,在干预后30天、60天、90天使用量表分别测量两组产妇的A评分,采用成组t检验比较两组产妇各时间点A评分变化。结果见表3.
研究者在不同时间点上多次测量了同一群产妇的A评分,观察时间属于重复测量因素,后一次测量的A评分不能排除是否会受到前一次测量的A评分的影响,故重复测量值之间并非独立的关系。若对不同时间点测量的A评分分别进行成组t检验,每个时点均比较不同方案的差异,将增加犯一类错误即假阳性错误的概率[11],且不能充分利用数据中的信息。该研究可应用上述纵向数据统计模型来分析受试因素的主效应、时间效应及主效应与时间效应之间的交互效应[12]。
2.2.4多组均数的比较采用t检验且未进行检验水准校正三组及以上均数的比较常使用单因素方差分析,但本研究发现有学者在对多样本均数进行比较时直接采用t检验,且未调整检验水准。
案例:为探究某植物提取物对抗缺氧损伤的作用,某研究者将实验细胞分为对照组、A组、B1组、B2组和B3组,并采用t检验对不同组别细胞培养液中指标一及指标二含量均数进行比较。数据见表4。
研究者使用t检验比较组间均数,并以P<0.05为差异有统计学意义,未校准检验水准,这样处理会放大I类错误,容易增加犯假阳性错误的概率[13]。多组间均数进行比较时,常使用方差分析判断各组间均数是否可以认为全部相等,若发现各组间均数不全部相等,则可以使用SNK-q检验、Dunnett-t检验等方法进一步做两两比较,确定是哪些组别有统计学差异[8]。若使用t检验处理多组间均数,则需采用Bonferroni法、Sidak法等对检验水准进行校准。以Bonferroni法为例,原文中对照组和B1组、B2组、B3组分别与A组比较指标物质含量,共计4次,故α’=0.0125。
3讨论
单因素统计推断是科学研究中最常见也是最基础的统计学方法,应用正确的单因素统计推断方法是保证研究结论真实性与有效性的基本要求[13]。本研究中公共卫生类期刊论文单因素统计推断错误发生率为4.65%,错误类型以不满足正态性或方差齐性误用t检验或方差分析、误用χ2检验与Fisher确切概率法最为常见,此外,由于调查范围有限等原因,等级资料误用χ2检验、配对设计误用成组t检验等常见单因素统计推断错误未在本研究中发现。吴红艳等[3]研究得到护理类期刊论文统计推断错误发生率为40.10%,其中计量资料的统计推断错误较常见,与本研究结果较为相似;张巧莲[5]对新疆医科大学学报文章的统计学方法应用问题进行调查,其统计推断错误发生率达12.70%。本研究中单因素统计推断错误发生率较低,究其原因一是其他研究未将范围限定于单因素统计推断,把多因素设计的统计分析方法也纳入研究,错误类型更多样化,故统计推断错误发生率更高;二是公共卫生人才受到更多统计学方面的训练,对统计分析方法掌握得更为熟练与牢固,因此公共卫生类期刊论文统计推断错误发生率略低于其他类型医学期刊论文;三是公共卫生类期刊的编辑与审稿专家有更多的统计学背景,往往能够在审稿阶段就发现问题并提出建议,让研究者及时改正错误;四是本研究选取的四种期刊在《2020中国学术期刊影响因子年报(自然科学与工程技术版)》中排名靠前,均为我国公共卫生与预防医学领域极具影响的专业性、权威性、综合性大型专业学术期刊,各个环节较普刊具备更高的要求,来稿往往也具有更高的质量。
为降低公共卫生类期刊论文单因素统计推断错误及其他统计学错误发生率,提高期刊文章质量,本研究建议:(1)研究者需要重视基本的统计学概念,而不是仅仅依赖统计学软件;加强统计学知识学习,综合考虑研究目的、研究设计类型和统计学方法的适用范围等因素,选用正确的统计学方法,并在文中明确表述。统计学专家应参与早期研究设计,因为此时的错误可能会对后续所有研究阶段造成负面影响[14]。(2)期刊编辑要夯实统计学基础,不断更新统计学知识储备,建立统一的编辑规范[15],通过手算或软件计算进行数据核查,提高统计学错误识别率,并与文章作者及时沟通,对出现严重设计失误或统计学错误的文章坚决退稿[16]。(3)审稿专家除文章内容外还应注重统计学方法的审查,尤其是具有统计学及流行病学背景的专家应对研究设计、应用条件、方法选择等环节把好关,提出修改的建议与意见,并对修改后的文章再次审查以保证文章质量。(4)期刊编辑部可以定期总结文章中的统计学错误及影响因素,动态观察期刊中发生统计学错误情况的变化,从中吸取教训不断改进。亦可增设专栏加强统计学应用的探讨,鼓励作者、读者来信,增进沟通与交流以共同进步。——论文作者:林春滢,蔡宇琪,刘元元,宛小燕
